Word Cloud-Generator für die
Veröffentlichungsdatenbanken
von IT.NRW
Lars Bartsch
15. März 2018
Überblick
Das R-Paket wordcloud
von Ian Fellows ist ein einfaches und elegantes Tool für die
randomisierte Erzeugung von Schlagwortwolken (engl.: tag cloud, word
cloud). Damit lassen sich die häufigsten Wörter insbesondere bei
umfangreichen Texten in einer zusammenfassenden grafischen
Visualisierung darstellen.
Zusammen mit dem R-Paket svglite
können diese Schlagwortwolken als extrem kleine SVG-Dateien
bereitgestellt werden. Die Texte bleiben erhalten (keine Pfadumwandlung)
und können komplett nachbearbeitet werden. Die SVG-Dateigröße von
svglite schrumpft im Vergleich zur
Standard-SVG-Schnittstelle von R auf ein Fünfundzwanzigstel (ca. 17
kb).
Im Folgenden möchte ich für die von IT.NRW betriebenen
Veröffentlichungsdatenbanken Landesdatenbank Nordrhein-Westfalen
(LDB), Regionaldatenbank Deutschland
(RDB) und Kommunale Bildungsdatenbank
(BDB) Schlagwortwolken mit zentralen Begriffen des jeweiligen
statistischen Datenangebots erzeugen. Da sich hier eine Gewichtung (=
Textgröße in der Cloud) nach Häufigkeiten nicht eignet, werden diese
Faktor manuell bestimmt. Die Farbgebung wird dem Corporate Design von IT.NRW angepasst.
Setup und Eingangsdaten
Setup
Zuerst kümmern wir uns um die benötigten R-Pakete. Das folgende Skript prüft, ob diese bereits auf dem System installiert sind. Fehlende Pakete werden direkt installiert und in die Session geladen. Gegebenenfalls müssen Pakete mit Administratorrechten installiert werden.
libs <- c("wordcloud", "svglite")
for (x in libs){
if(x %in% rownames(installed.packages()) == FALSE) {
print(paste0("installing ", x, "..."))
install.packages(x)
}
else{
print (paste0(x, " is already installed"))
}
library(x, character.only = TRUE)
}## [1] "wordcloud is already installed"
## [1] "svglite is already installed"Eingangsdaten
Als Eingangsdaten benötigen wir:
- drei Dateien mit den jeweiligen Begriffen der Datenbanken “[DB]”
sowie den Gewichtungen:
words_[DB].csv - drei Dateien mit den jeweiligen Farbpaletten für die Datenbanken
“[DB]” (RGB-Absolutwerte):
cali_[DB].csv
Für Komma-separierte Daten nutzen wir read.csv. Wegen
der deutschen Umlaute muss das Argument encoding gesetzt
werden.
terms_ldb <- read.csv("words_ldb.csv",
header=TRUE,
colClasses=c("character",
rep("numeric",2)),
encoding = "latin1")
terms_rdb <- read.csv("words_rdb.csv",
header=TRUE,
colClasses=c("character",
rep("numeric",2)),
encoding = "latin1")
terms_bdb <- read.csv("words_bdb.csv",
header=TRUE,
colClasses=c("character",
rep("numeric",2)),
encoding = "latin1")
terms_sc <- read.csv("words_sc.csv",
header=TRUE,
colClasses=c("character",
rep("numeric",2)),
encoding = "latin1")
knitr::kable(
head(terms_ldb), caption = "Ausschnitt aus der
Begriffsdatei der LDB."
)| word | mean | freq |
|---|---|---|
| Landesdatenbank NRW | 0.0 | 6 |
| Bevölkerung | 5.0 | 5 |
| Wirtschaft | 5.0 | 5 |
| VPI | 5.0 | 5 |
| Beschäftigte | 4.4 | 5 |
| Arbeitslose | 4.1 | 4 |
Die Farbpaletten müssen zunächst in Data Frames
calib_[DB] geladen werden
calib_ldb <- read.csv("cali_ldb.csv", header = TRUE)
calib_rdb <- read.csv("cali_rdb.csv", header = TRUE)
calib_bdb <- read.csv("cali_bdb.csv", header = TRUE)
knitr::kable(
head(calib_ldb), caption = "RGB-Werte für die
Farbgebung der LDB."
)| name | r | g | b |
|---|---|---|---|
| Schwarz | 0 | 0 | 0 |
| Grau | 218 | 218 | 218 |
| Blutorange | 232 | 78 | 15 |
| Grasgruen | 177 | 200 | 11 |
| Sonnengelb | 242 | 149 | 5 |
| Hausblau | 0 | 100 | 156 |
Erzeugen der Schlagwortwolken
Die Funktion set.seed() stellt die Reproduzierbarkeit
des Ergebnisses sicher. Der von wordcloud genutzte
R-Zufallszahlengenerator wird damit auf bestimmte Werte “fixiert”.
Die Skalierung der SVG-Abbildungen unterscheiden sich je nach dem, ob
die Abbildungen in das RMarkdown-Dokument oder in separate Dateien
exportiert werden. Mit scale = c([MAX], [MIN]) lässt sich
das Verhalten beeinflussen.
#set.seed(1034)
set.seed(5231)
clrs_ldb <- rgb(calib_ldb$r, calib_ldb$g, calib_ldb$b,
names = calib_ldb$name, max = 255)
wordcloud(words = terms_ldb$word,
freq = terms_ldb$freq,
min.freq = 1,
random.order = FALSE,
rot.per = 0.3,
scale = c(2.5,.3),
colors = clrs_ldb,
system_fonts = list(sans = "DejaVu Sans"))
set.seed(5231)
clrs_ldb <- rgb(calib_ldb$r, calib_ldb$g, calib_ldb$b,
names = calib_ldb$name, max = 255)
wordcloud(words = terms_sc$word,
freq = terms_sc$freq,
min.freq = 1,
random.order = FALSE,
rot.per = 0.3,
scale = c(2.5,.3),
colors = clrs_ldb,
system_fonts = list(sans = "DejaVu Sans"))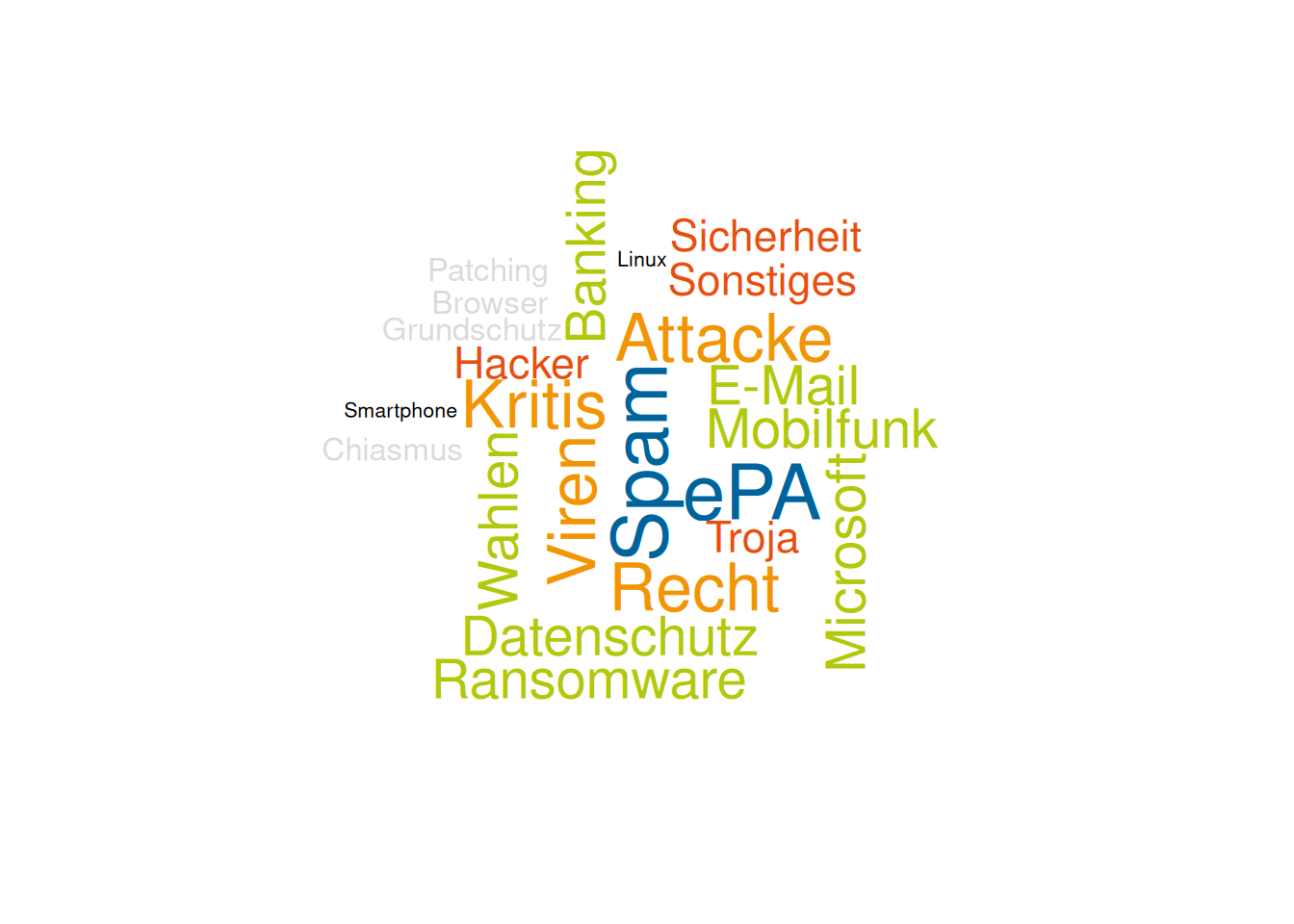
Für die zwei anderen Wolken passen wir die obere Größenklasse [MAX]
in scale an, damit die DB-Bezeichnungen die Breite
ausfüllen.
#set.seed(1034)
set.seed(5231)
clrs_rdb <- rgb(calib_rdb$r, calib_rdb$g, calib_rdb$b,
names = calib_rdb$name, max = 255)
#svglite("cloud_rdb2.svg")
wordcloud(words = terms_rdb$word,
freq = terms_rdb$freq,
min.freq = 1,
random.order = FALSE,
rot.per = 0.3,
scale = c(3.1,.3),
colors = clrs_rdb,
system_fonts = list(sans = "DejaVu Sans"))
#set.seed(1034)
set.seed(5281)
clrs_bdb <- rgb(calib_bdb$r, calib_bdb$g, calib_bdb$b,
names = calib_bdb$name, max = 255)
#svglite("cloud_bdb2.svg")
wordcloud(words = terms_bdb$word,
freq = terms_bdb$freq,
min.freq = 1,
random.order = FALSE,
rot.per = 0.3,
scale = c(3.1,.3),
colors = clrs_bdb,
system_fonts = list(sans = "DejaVu Sans"))
Ergebnis
Wie schon eingangs erwähnt, können die mittels svglite
auf Minimalgröße exportierten SVG-Dateien umfangreich nachbearbeitet
werden. Àlle wichtigen SVG-Attribute wie viewbox,
font-size, fill, font-family
sowie die Begriffe selbst stehen als indizierbare Elemente zur
Verfügung.
Systeminfo
## R version 4.3.3 (2024-02-29)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Manjaro Linux
##
## Matrix products: default
## BLAS: /usr/lib/libblas.so.3.12.0
## LAPACK: /usr/lib/liblapack.so.3.12.0
##
## locale:
## [1] LC_CTYPE=de_DE.UTF-8 LC_NUMERIC=C LC_TIME=de_DE.UTF-8 LC_COLLATE=de_DE.UTF-8 LC_MONETARY=de_DE.UTF-8
## [6] LC_MESSAGES=de_DE.UTF-8 LC_PAPER=de_DE.UTF-8 LC_NAME=C LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=de_DE.UTF-8 LC_IDENTIFICATION=C
##
## time zone: Europe/Berlin
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] svglite_2.1.3 wordcloud_2.6 highcharter_0.9.4 kableExtra_1.4.0 DT_0.32 stopwords_2.3 tidytext_0.4.1
## [8] RColorBrewer_1.1-3 ggthemes_5.1.0 lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4 purrr_1.0.2
## [15] readr_2.1.5 tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.0 tidyverse_2.0.0
##
## loaded via a namespace (and not attached):
## [1] tidyselect_1.2.1 viridisLite_0.4.2 farver_2.1.1 fastmap_1.1.1 janeaustenr_1.0.0 digest_0.6.35 timechange_0.3.0 lifecycle_1.0.4
## [9] tokenizers_0.3.0 magrittr_2.0.3 compiler_4.3.3 rlang_1.1.3 sass_0.4.9 tools_4.3.3 igraph_2.0.3 utf8_1.2.4
## [17] yaml_2.3.8 data.table_1.15.4 knitr_1.45 labeling_0.4.3 htmlwidgets_1.6.4 bit_4.0.5 curl_5.2.1 xml2_1.3.6
## [25] TTR_0.24.4 withr_3.0.0 grid_4.3.3 fansi_1.0.6 xts_0.13.2 colorspace_2.1-0 scales_1.3.0 cli_3.6.2
## [33] rmarkdown_2.26 crayon_1.5.2 generics_0.1.3 rlist_0.4.6.2 rstudioapi_0.16.0 tzdb_0.4.0 tufte_0.13 cachem_1.0.8
## [41] assertthat_0.2.1 parallel_4.3.3 vctrs_0.6.5 Matrix_1.6-5 jsonlite_1.8.8 hms_1.1.3 bit64_4.0.5 crosstalk_1.2.1
## [49] systemfonts_1.0.6 fontawesome_0.5.2 jquerylib_0.1.4 quantmod_0.4.26 glue_1.7.0 stringi_1.8.3 gtable_0.3.4 munsell_0.5.0
## [57] pillar_1.9.0 htmltools_0.5.8 R6_2.5.1 vroom_1.6.5 evaluate_0.23 lattice_0.22-5 highr_0.10 backports_1.4.1
## [65] SnowballC_0.7.1 broom_1.0.5 bslib_0.7.0 Rcpp_1.0.12 xfun_0.43 zoo_1.8-12 pkgconfig_2.0.3Dieses Werk ist lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License.